Noman Shabbir, Lauri Kütt, Muhammad Jawad, Oleksandr Husev, Ateeq Ur Rehman, Akber Abid Gardezi, Muhammad Shafiq and Jin-Ghoo Choi.
Abstract
Wind energy is featured by instability due to a number of factors, such as weather, season, time of the day, climatic area and so on. Furthermore, instability in the generation of wind energy brings new challenges to electric power grids, such as reliability, flexibility, and power quality. This transition requires a plethora of advanced techniques for accurate forecasting of wind energy. In this context, wind energy forecasting is closely tied to machine learning (ML) and deep learning (DL) as emerging technologies to create an intelligent energy management paradigm. This article attempts to address the short-term wind energy forecasting problem in Estonia using a historical wind energy generation data set. Moreover, we taxonomically delve into the state-of-the-art ML and DL algorithms for wind energy forecasting and implement different trending ML and DL algorithms for the day-ahead forecast. For the selection of model parameters, a detailed exploratory data analysis is conducted. All models are trained on a real-time Estonian wind energy generation dataset for the first time with a frequency of 1 h. The main objective of the study is to foster an efficient forecasting technique for Estonia. The comparative analysis of the results indicates that Support Vector Machine (SVM), Non-linear Autoregressive Neural Networks (NAR), and Recurrent Neural Network-Long-Term Short-Term Memory (RNN-LSTM) are respectively 10%, 25%, and 32% more efficient compared to TSO’s forecasting algorithm. Therefore, RNN-LSTM is the best-suited and computationally effective DL method for wind energy forecasting in Estonia and will serve as a futuristic solution.
Keywords: Wind energy production; energy forecast; machine learning
Introduction
The worldwide energy demand is increasing with every passing year so is the environmental pollution due to the brown energy generation from fossil fuels. Therefore, the uses of Renewable Energy Resources (RES) like solar and wind have gained popularity due to lower carbon emissions. However, wind energy generation is variable and unstable due to variations in wind speed [1,2]. The variable nature of wind depends on geographical area, weather, time of day, and season. Therefore, predicting wind power generation with 100% accuracy is a very difficult task [3]. However, this prediction is highly important for the management of demand and supply in power grids and also has an economic impact [4,5]. This prediction was usually made using statistical methods [6], such as moving average and autoregressive, but the accuracy of the models was relatively low. Machine learning (ML) based forecasting algorithms are a widely used tool due to their property to capture nonlinearities in the data with high accuracy, but machine learning algorithms usually require a large dataset of formation to develop an efficient forecasting model. These models are trained, validated, and tested; sometimes they still require retraining to obtain more precise results [7]. The forecasting models are usually divided into three categories, such as short-term forecasting (few minutes to 24 h), medium-term forecasting (days-ahead to week-ahead), and long-term forecasting (month-ahead to year-ahead) [8]. In this study, the real-time dataset of Estonian wind energy generation is used [9,10] for the development of these forecasting models.
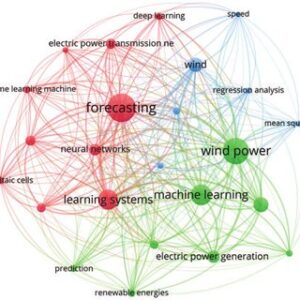
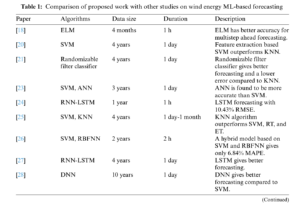
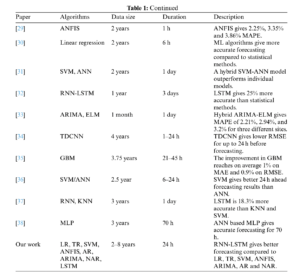
In the past, several research works have been developed using deep methods for wind speed forecasting and wind power generation forecasting. A bibliometric visualization of the keywords used in previous studies conducted in the past 5 years related to wind energy furcating has been made in VOS viewer software and depicted in Fig. 1. The figure shows the keywords used in 238 articles in the last five years related to wind energy forecasting. The forecasting of the wind speed in a university campus in Switzerland is being made using the ridge regression technique [11]. In a similar study [12], different ML algorithms like Support Vector Machine (SVM), K-Nearest Neighbor (KNN) regression, and random forest are compared for the forecasting of wind speed and corresponding energy generation for the day-ahead prediction horizon. A hybrid genetic algorithm and SVM-based algorithm are developed and tested for under-learning and overlearning scenarios of forecasting to determine the optimal solution [13]. A review of a supervised ML algorithm is made in [14]. In another work, ANN-based algorithms are developed and simulated to predict wind energy generation for grid stability [15]. A novel Cartesian genetic Artificial Neural Network (ANN) based algorithm is also proposed for wind energy forecasting in [16], which includes Hybrid regression based on SVM, Convolutional neural network (CNN), and singular spectrum analysis (SSA). The experimental results showed that SVM gave better predictions [17]. In [18], Extreme Machine Learning (ELM) algorithms have been used to forecast the wind speed for energy generation. A comparison of ELM, Recurrent Neural Networks (RNN), CNN, and fuzzy models is also given in [19–22] and future research directions are also explored. Tab. 1 provides a summary and comparison of the few known research articles related to wind energy forecasting using ML algorithms including Self-adaptive Evolutionary Extreme Learning Machine (SAEELM), Multilayer Perceptron (MLP), Random Forest (RF), Linear Regression (LR), Extremely Randomized Trees (ET), Radial Basis Function Neural Network (RBFNN), Gradient Boosting Algorithm (GBM), Tree Regression (TR), Long Short-Term Memory Networks (LSTM), Two-stream Deep Convolutional Neural Networks (TDCNN), Mean absolute percentage error (MAPE).
From all the above studies, it is clear that ML and DL algorithms are very useful in wind energy forecasting. However, it is still a very difficult thing to make an accurate prediction and a universal model is not possible. Therefore, every scenario requires a local dataset of wind speed, weather information, and location. Each model needs to be customized, built, and then trained. This accurate forecasting will help in the better management of demand and supply, smooth operation, flexibility and reliability and as well as economic implication.
In this research, a comparison has been made between different machine learning and DL forecasting algorithms for a day-ahead wind energy generation in Estonia. The historical data set on one-year Estonian wind energy generation was taken from the Estonian Transmission System operator (TSO) called ELERING [9]. This historical data contains all of the above-stated factors that affect wind energy generation. On the basis of this data, different forecasting algorithms are modeled, trained, and compared.
The key contributions of this paper are summarized as follows:
• To address the problem of wind energy forecasting in Estonia, state-of-the-art ML and DL algorithms are implemented and rigorously compared based on performance indices, such as root mean square error, computational complexity, and training time.
• A detailed exploratory data analysis is conducted for the selection of optimal models’ parameters, which proves to be an essential part of all implemented ML and DL algorithms.
• A total of six ML NAR and two DL algorithms are implemented, such as linear regression, tree regression, SVM, ARIMA, AR, NAR, ANFIS, and RNN-LSTM. All implemented algorithms are thoroughly compared with currently implemented TSO forecasted wind energy and our proposed RNN-LSTM forecasting algorithm proves to be a more accurate and effective solution based on performance indices.
Machine Learning Algorithms for Forecasting
The most common ML tool for forecasting is regression-based algorithms [19]. Regression-based learning is categorized into supervised learning algorithms that use past data sets of the parameters in the training of the model and then predict the future values of the parameters based on the regressed time lag values of the parameters, where the number of lag selections is based on observation. Moreover, the most used DL algorithms in time series prediction are RNN and CNN. In CNN, the output only depends on the current input while in RNN, the output depends both on the current and previous values that provide an edge to RNN in time series prediction. In this section, machine learning and deep learning algorithms used in this study are elaborated.
Linear Regression
This simplest and most commonly used algorithm computes a linear relationship between the output and input variables. The input variables can be more than one. The general equation for linear regression is along with its details can be found in [7].
Tree Regression
This algorithm deploys a separate regression model for the different dependent variables, as these variables could belong to the same class. Then further trees are made at different time intervals for the independent variables. Finally, the sum of errors is compared and evaluated in each iteration, and this process continues until the lowest RMSE value is achieved. The general equation and the details of the algorithm are described in [7].
Support Vector Machine Regression (SVM)
SVM is another commonly used ML algorithm due to its accuracy. In SVM, an error margin called ‘epsilon’ is defined and the objective is to reduce epsilon in each iteration. An error tolerance threshold is used in each iteration as SVM is an approximate method. Moreover, in SVM, two sets of variables are defined along with their constraints by converting the primal objective function into a Lagrange function. Further details of this algorithm are given in [7,39,40]:
Recurrent Neural Networks
The RNN is usually categorized as a deep-learning algorithm. The RNN algorithm used in this paper is the Long Short-Term Memory (LSTM) [41]. In LSTM, the paths for long-distance gradient flow are built by the internal self-loops (recurrences). In this algorithm, to improve the abstract for long time series based different memory units are created. In conventional RNN, the gradient vanishing problem is a restriction on the RNN architecture to learn the dependencies of the current value on long-term data points. Therefore, in LSTM, the cell data are kept updated or deleted after every iteration to resolve the vanishing gradient issue. The LSTM network in this study consists of 200 hidden units that were selected based on the hit-and-trial method. After 200 hidden units, no improvement in the error is observed.
Autoregressive Neural Network (AR-NN)
This algorithm uses feedforward neural network architecture to forecast future values. This algorithm consists of three layers, and the forecasting is done iteratively. For a step ahead forecast, only the previous data is used. However, for the multistep ahead, previous data and forecasted results are also used, and this process is repeated until the forecast for the required prediction horizon is achieved. The mathematical relationship between input and output is as follows [42]:
yt=w0+h∑j=1wj.g(w0,j+n∑i=1wi,j.yt−1)+εtyt=w0+∑j=1hwj.g(w0,j+∑i=1nwi,j.yt−1)+εt(1)
where wi.j,wj(iwi.j,wj(i,jj = 0, 1, 2,…, n, j = 1, 2, …, hh) are parameters for the model; n represents the input nodes, h is the number of hidden nodes. In addition, a sigmoid function is used for the hidden layer transfer function as defined in Eq. (2) [42].
sig(x)=11+exp(−x)sig(x)=11+exp(−x)(2)
Non-Linear Autoregressive Neural Network
The Nonlinear Autoregressive Neural Network (NAR-NN) predicts the future values of the time series by exploring the nonlinear regression between the given time series data. The predicted output values are the feedback/regressed back as an input for the prediction of new future values. The NA-NN network is designed and trained as an open-loop system. After training, it is converted into a closed-looped system to capture the nonlinear features of the generated output [43]. Network training is done by the back-propagation algorithm mainly by the step decent or Levenberg-Marquardt back-propagation procedure (LMBP) [44].
Autoregressive Integrated Moving Average (ARIMA)
This model is usually applied to such datasets that exhibit non-stationary patterns like wind energy datasets. There are mainly three parts of the ARIMA algorithm. The first part is AR where the output depends only on the input and its previous values. Eq. (3) defines an AR model for the p-order [45]:
yt=c+∅1yt−1+∅2yt−2+…∅pyt−p+∈tyt=c+∅1yt−1+∅2yt−2+…∅pyt−p+∈t(3)
where tt is the number of lags, Ø is the coefficient of the lag, c is the intercept term and ∈t∈t is white noise. MA is the second part that describes the regression error as a linear combination of errors at different past time intervals. Eq. (4) [45] describes the MA as follows,
yt=∈t+∅1∈t−1+∅2∈t−2+…∅p∈t−pyt=∈t+∅1∈t−1+∅2∈t−2+…∅p∈t−p(4)
The third part ‘I’ describes that the data have been updated by the amount of error calculated at each step to improve the efficiency of the algorithm. The final equation of ARIMA is as follows [45]:
yt=c+∅1yt−1+∅2yt−2+…∅pyt−p+∅1∈t−1+∅2∈t−2+,…,∅p∈t−pyt=c+∅1yt−1+∅2yt−2+…∅pyt−p+∅1∈t−1+∅2∈t−2+,…,∅p∈t−p(5)
Adaptive Neuro-Fuzzy Inference System (ANFIS)
This algorithm is a hybrid of ANN and Fuzzy logic. In the first step, Takagi and Sugeno Kang’s fuzzy inference modeling method is used to develop the fuzzy system interference [46]. The overall model in this algorithm consists of three layers. The first and last layers are adaptable and can be modified accordingly to the design requirements while this middle layer is responsible for the ANN and its training. In the fuzzy logic interference system, the fuzzy logic structures and rules are defined. Moreover, it also includes fuzzification and defuzzification as well.
This algorithm works on Error Back-propagation (EPB) model. The model employs Least Square Estimator (LSE) in the last layer which optimizes the parameters of the fuzzy membership function. The EBP reduces the error in each iteration and then defines new ratios for the parameters to obtain optimized results. However, the learning algorithm is implemented in the first layer. The parameters defined in this method are usually linear [46,47].
Exploratory Data Analysis
Estonia is a Baltic country located in the northeastern part of Europe. Most of its energy is generated from fossil fuels, whereas the RESs are also contributing significantly. The average share of fossil fuels is around 70% for the year 2019, while renewables are around 30% [9]. Although 30% is still higher as per the EU plan for renewable integration in the grid by 2020 [9]. As per the 35% share in RE, wind energy is the second most used resource in Estonia after biomass in 2019 [9], which makes it very important. The energy demand in Estonia is usually high in winter and the peak value is around 1500 MWh, while the average energy consumption is around 1000 MWh. Meanwhile, the average energy generation is around 600 MWh and the peak value is around 2000 MWh [9]. The demand and supply gap can vary between 200 to 600 MWh and is almost the same throughout the year. This gap is overcome by importing electricity from Finland, Latvia, and Russia if needed [9].
In Estonia, a total of 139 wind turbines are currently installed, mainly along the coast of the Baltic Sea [10]. Fig. 3 shows the geographical location of the installed sites. The installed capacity of these wind turbines is around 301 MW. In addition, there are 11 offshore and two offshore projects under the development phase. The plan is to have 1800 MW of wind power generation by the year 2030 [10]. The current share of wind energy is only around 10% of the total energy generated in Estonia. However, according to EU regulations, environmental factors, and self-dependency, this share will increase rapidly in the future. Therefore, due to the stochastic nature of wind speed, accurate prediction of wind power generation will be essential to manage demand and supply. A good and advanced prediction technique is required for an accurate wind power generation prediction in Estonia. This study provides a detailed and wide exploratory and comparative analysis for wind power generation forecasting by employing multiple linear and nonlinear ML and Deep Learning (DL) techniques.
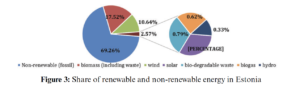
The data set used in this article is the Estonian general data on wind energy generation from 1 January 2011 to 31 May 2019. The frequency of the data set is one hour. This data set for wind energy generation is highly variable due to the weather conditions in Estonia. The maximum value of wind energy production in the aforementioned period is nearly 273 MWh, the mean value is 76.008 MWh, the median is 57.233 MWh, and the standard deviation is 61.861 MWh. To demonstrate the variable nature of the time series dataset for Estonian wind power generation, the moving average and the moving standard deviation are the best tools to elaborate on this dynamic nature of the dataset. Fig. 4 shows the wind energy production data along with the moving average and the moving standard deviation from Jan. 2018 to May 2019. It is clear from Fig. 4 that there are no clear peaks in wind energy or low seasonal values. Wind energy production is variable throughout the whole year. As indicated by the moving average, wind energy generation is high in winter (November to March), but even in that time, its value drops for a few weeks and then again increases.
The histogram and the probability density function (PDF) of the data are shown in Fig. 5a, which indicates that the wind energy production is below 50 MWh most of the time and its value rarely goes above 250 MWh. The histogram data is now normalized to compute the actual probability of different energy production values. The resultant probabilities are depicted in Fig. 5b. These probability values also indicate the same analogy. For example, the probability of getting 100 MWh energy is around 20% and 250 MWh is only around 3%. Therefore, the accuracy for the prediction of peak power generation or above-average power generation is a challenging task. Further analysis of this data set is performed using autocorrelation analysis. Fig. 5c shows the autocorrelation analysis of the data set.
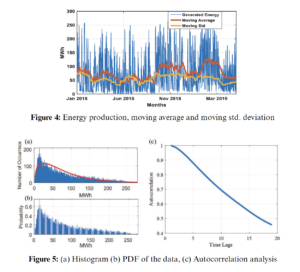
In time-series analysis, the autocorrelation measure is a very useful tool to observe the regression nature of the time-series data and provides a birds-eye view for the election of the number of lags if any regression-based forecasting model is employed. It is the correlation of the signal with its delay version to check the dependency on the previous values. In this graph, the lag of 20 h is shown, in which the lags up to the previous 16 h have a regression value above 0.5 percent and after which it drops significantly below 0.5. The confidence interval is identified by the calculated 2 values. The correlation decreases slowly over time, which shows long-term dependency. The description of this observation is described in [48]. However, the autocorrelation of wind energy generation does not decrease rapidly with weather changes related to different seasons. This exploratory data analysis helps us to estimate design, and parameter selection for all ML and deep-learning algorithms defined earlier.
Forecasting of Wind Energy
The Estonian wind energy dataset has been used in this research. The dataset is then divided into training, testing and validation and the divisions of data are 80%, 10% and 10%, respectively. All these simulations are carried out in Matlab2021a in a Windows 10 platform running on an Intel Core i7-9700 CPU with 64 GB RAM. Initially, the training data was converted into standard zero mean and unit variance form to avoid convergence in the data. The same procedure was carried out for the test data as well. The prediction features and response output parameter has also been defined for a multistep ahead furcating. The Estonian TSO is responsible for the forecasting of wind energy generation on an hourly basis. Their prediction algorithm forecasts wind energy generation 24 h in advance. It also generates the total energy production and the anticipated energy consumption. Fig. 6 shows the values of wind energy production and the values forecasted by the TSO algorithm for May 2019 [49].
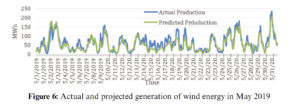 Most of the time, the actual energy generation is much higher than the forecast values. The gap can go up to 70 MWh, which is too much. The forecasting algorithms need to be more accurate than that. This variation can falsely tell the energy supplier to use alternative energy sources rather than wind. This may be fossil fuel or any other resource, which will cost more to the supplier and eventually the customer. This low accuracy allowed us to study, develop, and propose a comparatively suitable forecasting algorithm for the prediction of wind power generation in Estonia.
Most of the time, the actual energy generation is much higher than the forecast values. The gap can go up to 70 MWh, which is too much. The forecasting algorithms need to be more accurate than that. This variation can falsely tell the energy supplier to use alternative energy sources rather than wind. This may be fossil fuel or any other resource, which will cost more to the supplier and eventually the customer. This low accuracy allowed us to study, develop, and propose a comparatively suitable forecasting algorithm for the prediction of wind power generation in Estonia.
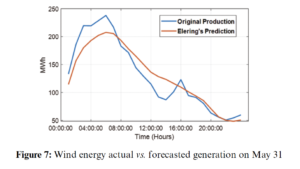
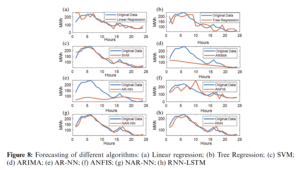
In this study, the emphasis is on the accurate prediction of wind energy generation in Estonia. Eight different algorithms based on machine learning and DL are simulated and tested using the 1-year wind energy generation data set for a day-ahead prediction horizon. The results of all employed algorithms are compared based on RMSE values. Fig. 7 shows the comparison of actual wind energy generation and the forecast wind energy generation of TSO for 31 May 2019. It is clear from the figure that there is a substantial gap between the original and predicted values. The RMSE value for TSO forecasting is 20.432. The forecasting of all algorithms is tested on the same day as shown in Fig. 8.
Results and Discussions
The wind power generation data understudy has a highly nonlinear nature; therefore, a vast variety of linear and nonlinear forecasting algorithms need to be tested to find an appropriate option. A thorough comparative analysis is conducted to compare the accuracies of all forecasting algorithms employed in this paper. Machine learning algorithms, such as linear regression, AR, ARIMA, and tree-based regression, are not performed adequately, while SVM is given good forecast accuracy.
On the contrary, deep-learning algorithms, such as NAR and RNN, have a high degree of accuracy compared to all other algorithms employed as the architectures for both algorithms have the capability to capture nonlinear features of the data. However, the ANFIS also gives relatively low accuracy. The ML algorithms are not showing accuracy as the data is highly non-linear and therefore the ML algorithms do not perform better curve fitting and result in lower accuracy as compared to DL methods.
DL models, in contrast, due to the ANN fitted the curve better and therefore gave more accurate forecasting results. Thus, these results indicate that for this time series-based forecasting the efficiency of DL methods is higher as compared to ML methods. The comparative analysis of ML algorithms and DL algorithms based on the RMSE value is depicted in Tab. 2. In addition, to the best of the author’s knowledge, this study is the first comprehensive comparative analysis between the know ML and DL algorithms for wind power generation data in Estonia.
Furthermore, it is pertinent to mention that this energy forecasting topic has been under investigation for decades. The main issue is still the accuracy of forecasting. The main focus is to forecast wind energy on the basis of past data and not wind speed. Some researchers have tried to develop some hybrid models as well. However, it is extremely difficult to compare the results of these studies with our study as there are many parameters involved like the size of the dataset, location, time span, and then the algorithm used.
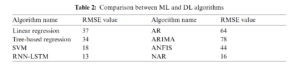
In this study, the best results are shown by the RNN-LSTM algorithm. The algorithm consists of 100 hidden units in the LSTM layer. This number of hidden units is obtained by the hit and trial method, the numbers are varied from 20 to 250. The models showed the best results for 100 units and after that, the results remained almost the same. It is using historical data only. Therefore, the number of features is one and the response is also one. The training of the algorithm is carried out by an ‘ADAM’ solver and the number of Epochs was also varied from 50–250 epochs. When the whole data set passes through the back or forward propagation through the neural network then it is called an Epoch. Learning rate is used to train the algorithm and when a certain number of Epochs are passed then it is dropped to a certain value. The initial learning rate was defined as 0.005. The gradient threshold is also one. The simulation parameters are described in Tab. 3.
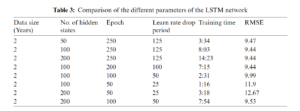
In order to make multistep predictions, the prediction function makes a forecast of a single time step; and then updates the status of the network after each prediction. Now, the output of the first step will act as the input for the next step. The size of the data is also varied and tested between 1 month and 96 months to observe its impact on the forecasting algorithm. The simulation results show that after the data size is more than 24 months, the performance of this algorithm does not affect. Almost, the same RMSE value is obtained for 36, 60, and 96 months. The comparison is shown in Tab. 4. The RMSE values and the corresponding training time are also shown in Tab. 4.
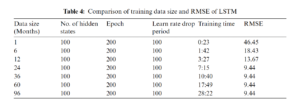
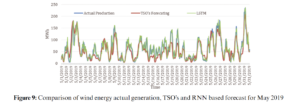
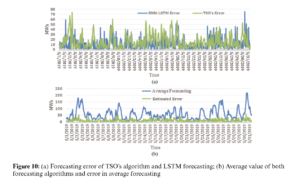
Fig. 9 shows the compression of actual wind energy production of TSO, the forecasted production and our algorithm for May 2019. It is clear from the graph that RNN-LSTM is providing better forecasts throughout the month. The RMSE value of the TSO furcating is 25.18 while the RNN forecasting is 15.20 for the whole month. Fig. 10a shows the error of both the TSO forecasting algorithm and the proposed RNN-LSTM algorithm. It is also clear from the graph that TSO’s forecasting error is higher. The TSO’s algorithm predicts a small variation in output energy well but fails when there are large fluctuations. On the other hand, RNN-LSTM is forecasting the large functional well but sometimes does not work that well with continuous low values of energy prediction. Therefore, a hybrid of both algorithms can be proposed here that will overcome both the low and high fluctuation. The results are shown in Fig. 10b. The error in forecasting is also depicted here. The error in forecasting is quite low now as is observed from the graph. The RMSE value for this hybrid forecasting is 8.69.
Conclusions
In the past decade, ML and DL have become promising tools for forecasting problems. The highly nonlinear behavior of weather parameters especially wind speed makes it a valid challenging problem to use ML and DL algorithms for wind energy forecasting for smart grids. Moreover, an accurate time-series forecasting algorithm can help provide flexibility in modern grids and have economical and technical implications in terms of demand and supply management and for the study of power flow analysis in power transmission networks. In this paper, six ML and two DL forecasting algorithms are implemented and compared for Estonian wind energy generation data.
Wind energy accounts for approximately 35% of total renewable energy generation in Estonia. This is the first attempt to provide an effective forecasting solution for the Estonian energy sector to maintain power quality on the existing electricity grid. We target the day-ahead prediction horizon, which is the normal practice for the TSO forecasting wind energy model. Real-time year-long wind energy generation data are used for the comparative analysis of the ML and DL algorithms employed. Moreover, the results of all employed models are also compared with the forecasting results of TSO’s algorithm. The comparison of all ML and DL algorithms is based on performance indices, such as RMSE, computational complexity, and training time. For example, the results for May 31, 2019, illustrated that TSO’s forecasting algorithm has an RMSE value of 20.48. However, SVM, NAR, and RNN-LSTM have lower RMSE values. The results conclude that SVM, NAR, and RNN-LSTM are respectively 10%, 25%, and 32% more efficient compared to TSO’s forecasting algorithm. Therefore, it is concluded that the RNN-LSTM based DL forecasting algorithm is the best-suited forecasting solution among all compared techniques for this case.
Related Topics
Empower Your Business with Our Innovative IT Solutions!

- Cloud Services
- ServiceNow Integrations
- AI Implementation on Azure OpenAI